- 公開日
- 最終更新日
【AWS re:Invent 2025】CloudWatch Investigations による RCA 自動化
この記事を共有する

目次
Amazon CloudWatch(以降、CloudWatch)では、Application Signals を中心に、 可観測性データを統合して扱う構成が提供されています。
re:Invent 2025で開催されたセッション「AI-Driven Root Cause Analysis(COP320)」では、 CloudWatch Investigations を使ったRCA(根本原因分析)の流れを CloudWatch コンソール上で確認しました。
CloudWatch Investigations は、SLO の悪化を起点に、ログ・メトリクス・トレースを横断的に分析し、 原因候補と根拠を自動で整理する機能です。
CloudWatch Investigations の位置づけ
Investigations は、CloudWatch が提供する可観測性(Observability)機能群の一部として位置づけられています。以下の図は、CloudWatch が収集・管理する可観測性データの全体像です。
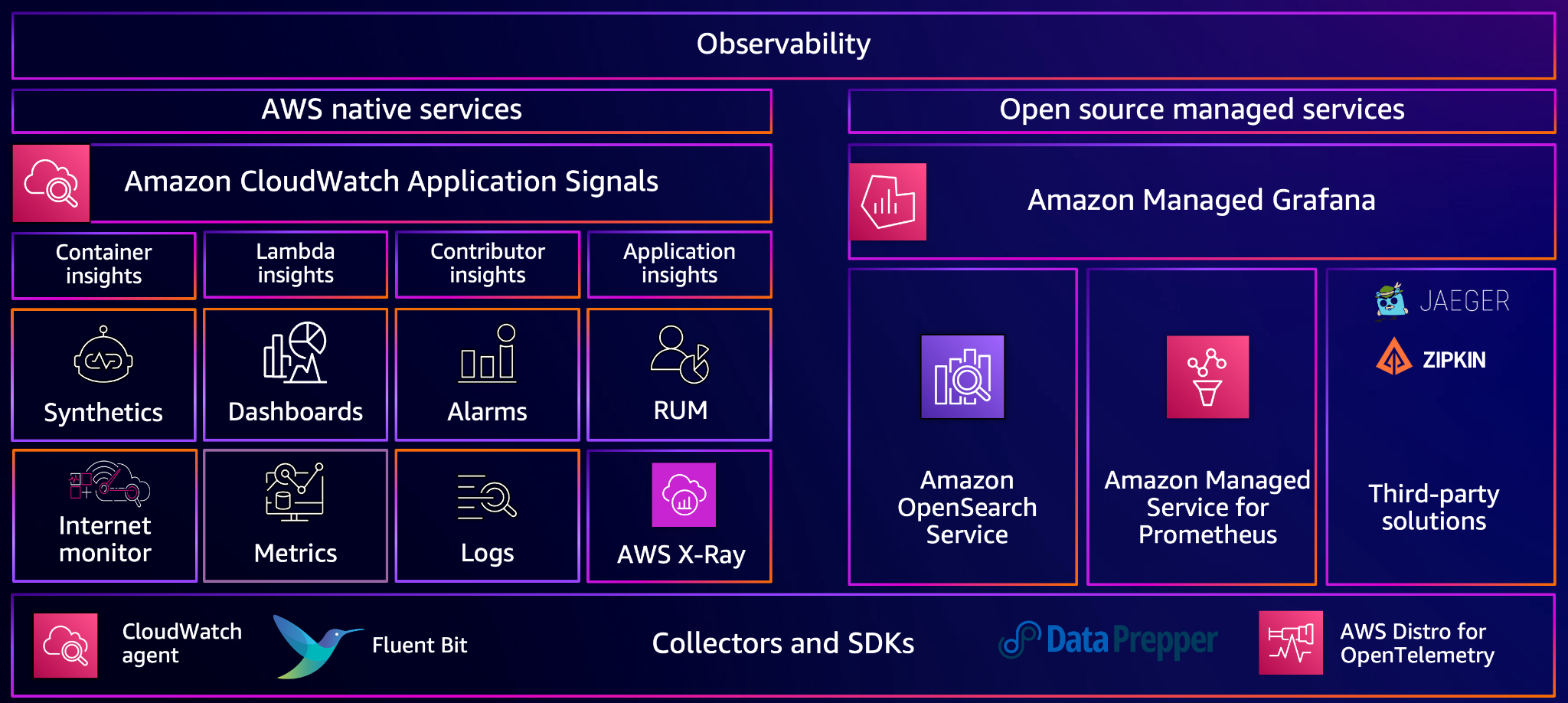
Investigations は、 Application Signals が算出した SLO やサービスの健全性といった「状態」を起点に、自動で以下を実行します。
- 異常期間の特定
- 関連ログの抽出
- トレースから遅延箇所を検出
- トポロジ上の影響範囲の強調表示
- Hypothesis(原因候補)の提示
- Evidence(根拠)の整理
ハンズオンを進めながら理解する
AWS が用意した EKS 上の 「PetClinic」という アプリケーションを対象に Application Signals と Investigations を利用します。
このサンプル環境では、CloudWatch Observability Addon により コード変更なしでログ・メトリクス・トレースが収集され、 Investigations の分析対象となっています。
調査対象となるサンプルアプリケーション構成
この構成図は、 Investigations が分析に利用する 可観測性データがどこから集約されるかを示しています。
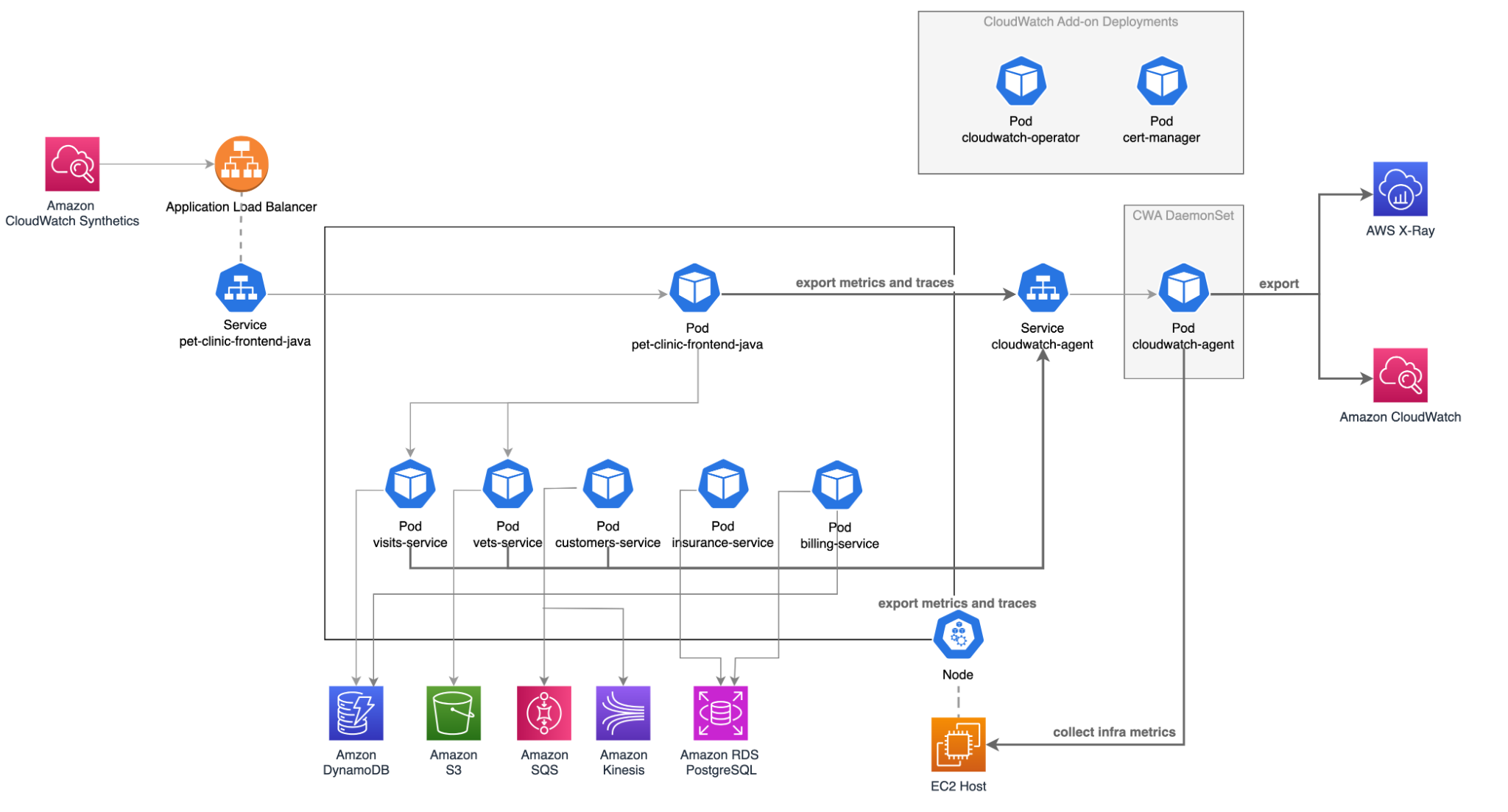
中央に並ぶマイクロサービス群(各 Pod)から発生する ログ・メトリクス・トレースは、 右側に配置された CloudWatch Agent により収集され、 図の右端にある CloudWatch および X-Ray に集約されます。
図に示されていませんが、Application Signals は、CloudWatch に集約されたこれらのデータを基に サービス単位の健全性や SLO を算出します。 Investigations は、その SLO の悪化を起点として、 原因調査をおこないます。
SLO の設定
SLO(Service Level Objective)は可用性や遅延などの目標値で、異常検知の起点です。 PetClinic サンプルアプリケーション内の1マイクロサービス名「nutrition-service-nodejs」 に可用性 SLO(99.9%)が設定されており、 SLO が急落したタイミングから調査を開始します。
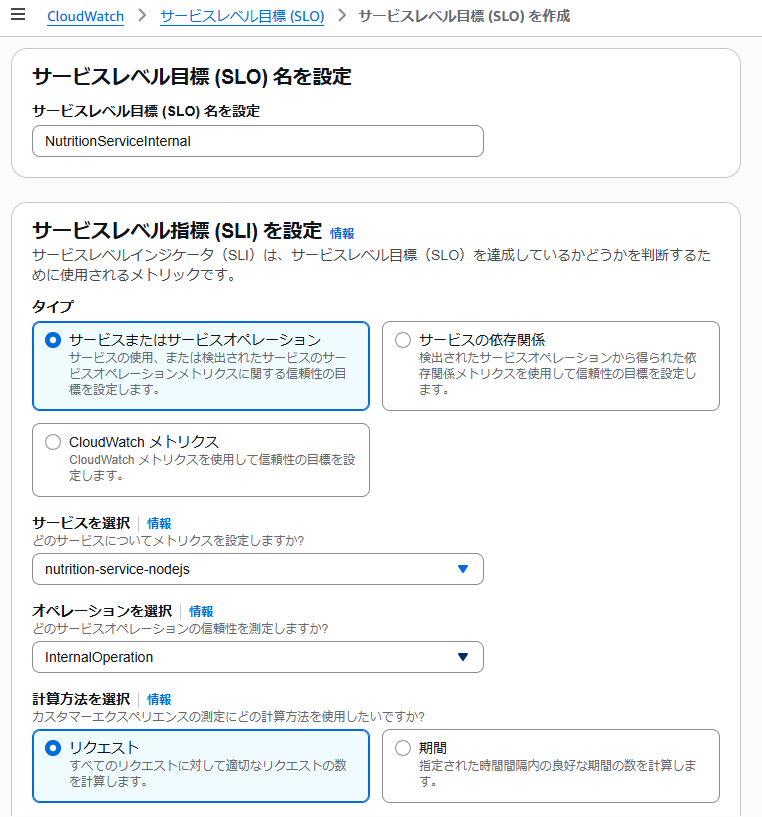
MongoDB 接続エラーを発生させてみる
このシナリオでは、「nutrition-service-nodejs」 の可用性 SLO が低下したことを起点に、 CloudWatch Investigations を用いて原因調査をおこないました。
1. SLO の悪化を起点に調査を開始
Application Signals により、「nutrition-service-nodejs」 に設定された 可用性 SLO(99.9%)が短時間で大きく低下しました。Investigations では、この SLO を起点に調査を開始しました。
2. CloudWatch コンソールから調査を開始
SLO の画面から 「Start investigation」 を選択すると、 CloudWatch Investigations が自動的に分析を開始します。
この時点で運用者が行う操作は、 調査の開始ボタンを押すことだけです。

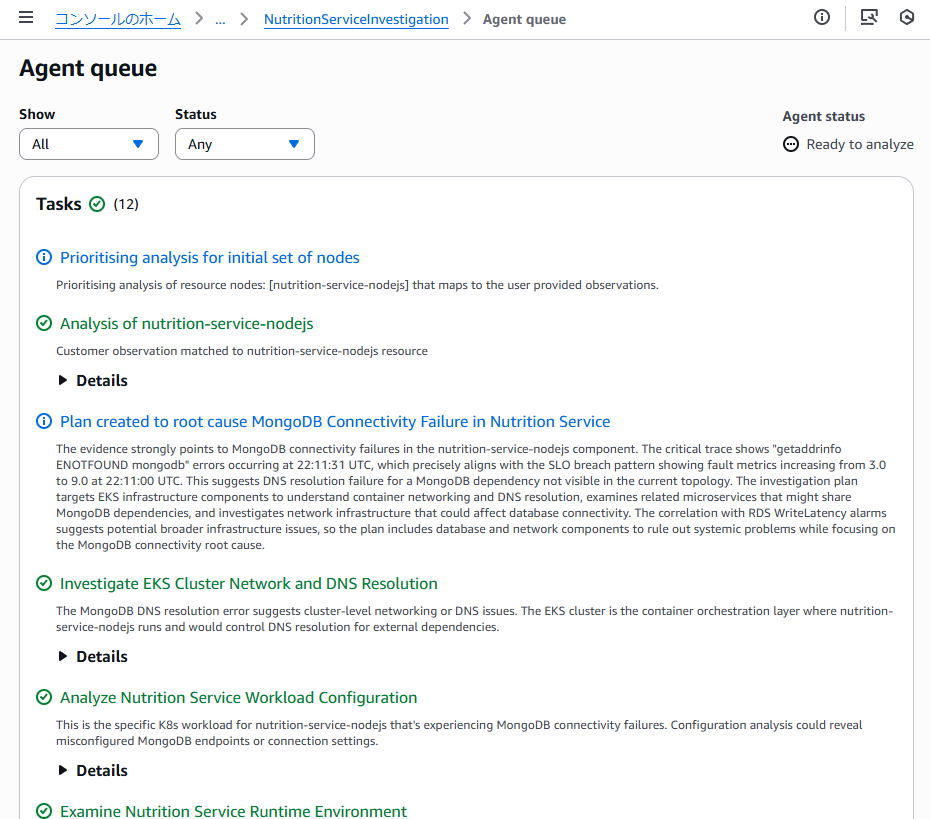
Investigations は裏側で以下の処理を実行します。
- 異常が発生した時間帯の特定
- 関連するメトリクス・ログ・トレースの収集
- サービス間の依存関係の解析
- 調査対象サービス周辺の異常箇所の抽出
3. Hypothesis(原因候補)の提示
調査が進むと、Investigations は Hypothesis として MongoDB への接続障害を原因候補として提示します。
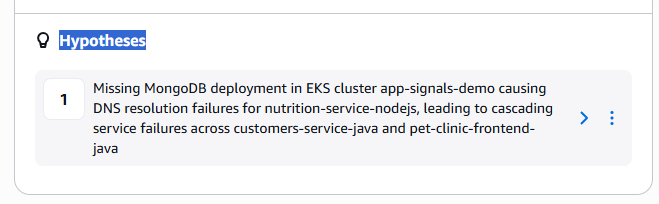
Hypothesis には、次の情報が整理された形で表示されます。
- どのサービスが影響を受けたか
- どの依存リソースが関連しているか
- 問題が発生した時間帯
- 影響が SLO にどのように現れたか
原因を断定するのではなく、 最も可能性が高い候補として提示される点が重要です。
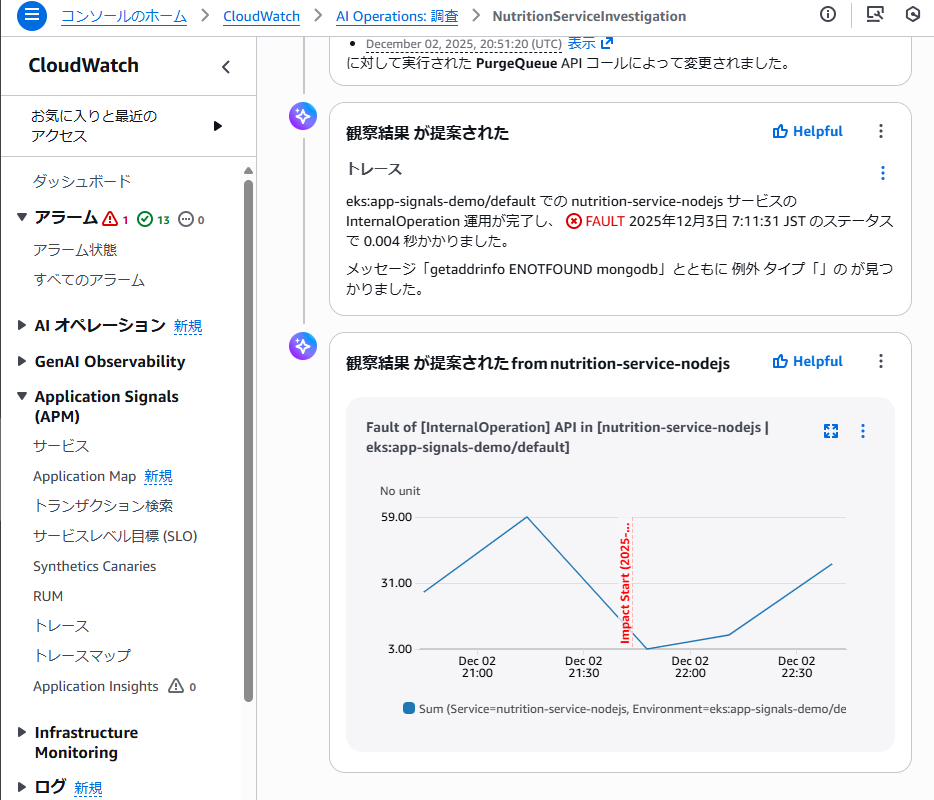
4. Evidence(根拠)の確認
Hypothesis を選択すると、 その裏付けとなる Evidence が確認できます。 Evidence として提示された内容は以下のとおりです。
- MongoDB 接続エラーを示すアプリケーションログ
- トレース上で確認できる処理遅延
- 依存関係トポロジにおける MongoDB ノードの強調表示
- エラー率の上昇と SLO 低下の時間的な一致
これらは調査画面上で関連付けられた状態でレポートのように表示されます。
5. 人が行う判断ポイント
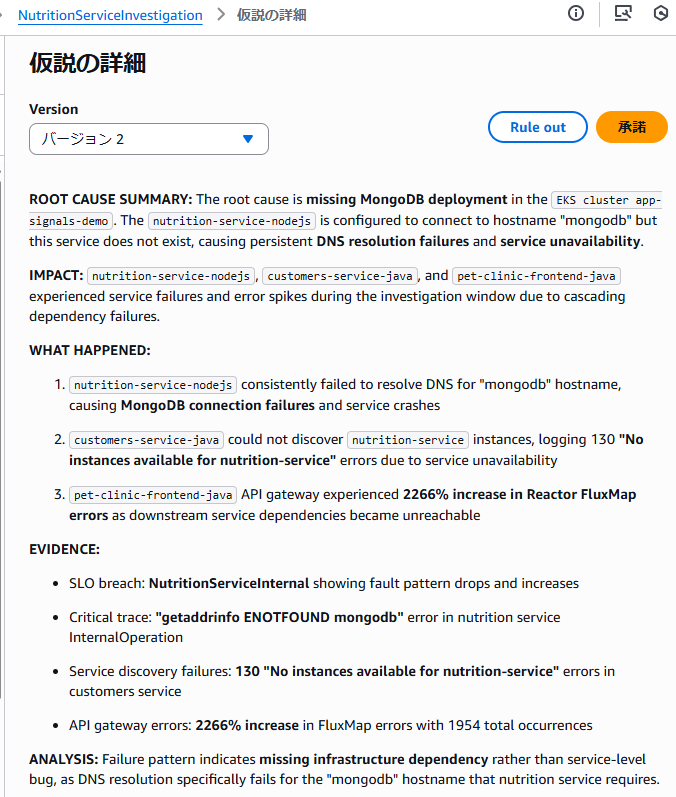
Investigations が提示するのは、 あくまで調査結果の整理と原因候補です。 最終的に運用者が行うのは、以下の内容です。
- 提示された Hypothesis が妥当かの判断
- Evidence の内容確認
- 再発防止策や対応方針の検討
調査の初動が自動化されることで、 人は「調べる作業」ではなく 「判断と改善」に集中できる構成になっています。
Investigations が自動化する範囲と、人間の判断範囲
自動化される部分
- 異常発生期間の特定
- テレメトリの収集
- サービス間の依存関係分析
- Hypothesis の提示
- Evidence の整理
- 調査レポートの生成
人間が判断する部分
- 原因候補の確度の確認
- 再発防止策の検討
- SLO/SLI の見直し
- 対応優先度の判断
Investigations は初動調査を効率化し、 判断業務を明確に切り分けるための仕組みです。
まとめ
COP320 では、CloudWatch Investigations を利用した 根本原因分析のプロセスを CloudWatch コンソール上で確認しました。 異常検知から原因候補の提示までが自動化され、 運用者は判断と改善に集中できます。
Investigations は、AIを活用した運用を 既存の CloudWatch の監視を活かしながら導入できる点で、実務に適した内容だと感じました
この記事は私が書きました
河野 桂子
記事一覧ヨシ!
