- 公開日
- 最終更新日
【Bedrock AgentCore Memory】エピソード記憶戦略をもちいたAI Agent改善
この記事を共有する

目次
はじめに
皆さんこんにちは!パーソル&サーバーワークスの小泉です。
【Strands Agents】ブログレビューエージェントを作った際の学びで作成したAI Agentで社内ブログのレビューを実施しています。
運用してみて、嬉しいことにブログレビューの観点に○○を入れて等の要望もあり、継続的に依頼がきています。
しかし、順次観点を増やすとなると「コードの修正→デプロイ」という流れが必須になってきます。
この流れが煩わしいと考えたので、最近でたBedrock AgentCore Memoryのエピソード記憶戦略を利用すれば、「コードの修正→デプロイ」という流れをなくせるのではないかと考えたので検証した内容を記載します。
Bedrock AgentCore Memoryとは
Bedrock AgentCore Memoryは、AI Agentに「記憶」を持たせるためのマネージドサービスです。
Memoryは短期記憶と長期記憶があります。
短期記憶から長期記憶へと情報を処理する方法を記憶戦略と呼びます。
この記憶戦略は現在4つの戦略がサポートされています。
Semantic memory strategy:会話から重要な事実と文脈知識を抽出
User Preference Memory strategy:ユーザーの好み・選択・スタイルを識別
Summary Memory strategy:セッション内の会話をリアルタイムで要約
Episodic Memory strategy:重要な会話の瞬間だけを選別して記録し、ノイズを排除しながら文脈を保持
やりたいこと
ブログレビューエージェントに対して、レビュー観点をユーザーがコードの改修なしに追加できるようにしたい。
解決方法(想定)
Bedrock AgentCore Memoryのエピソード記憶戦略を利用する。
Bedrock AgentCore Memoryにユーザがレビュー観点をテキスト形式で入力を行う。
レビュー時にエージェントが記憶されているレビュー観点を確認し、レビューを行う。
これにより、誰でもレビュー観点を容易に追加でき、自動でエージェントがレビュー観点を増やしてくれる。
検証内容
今回の検証では、以下2点について確認します。
- ユーザがメモリにレビュー観点を入れる方法
- メモリに何が記憶されているかを確認する方法
検証
メモリにレビュー観点を入れる方法
まずはBedock AgentCoreからメモリを作成しました。
マネジメントコンソールから簡単に作成できます。
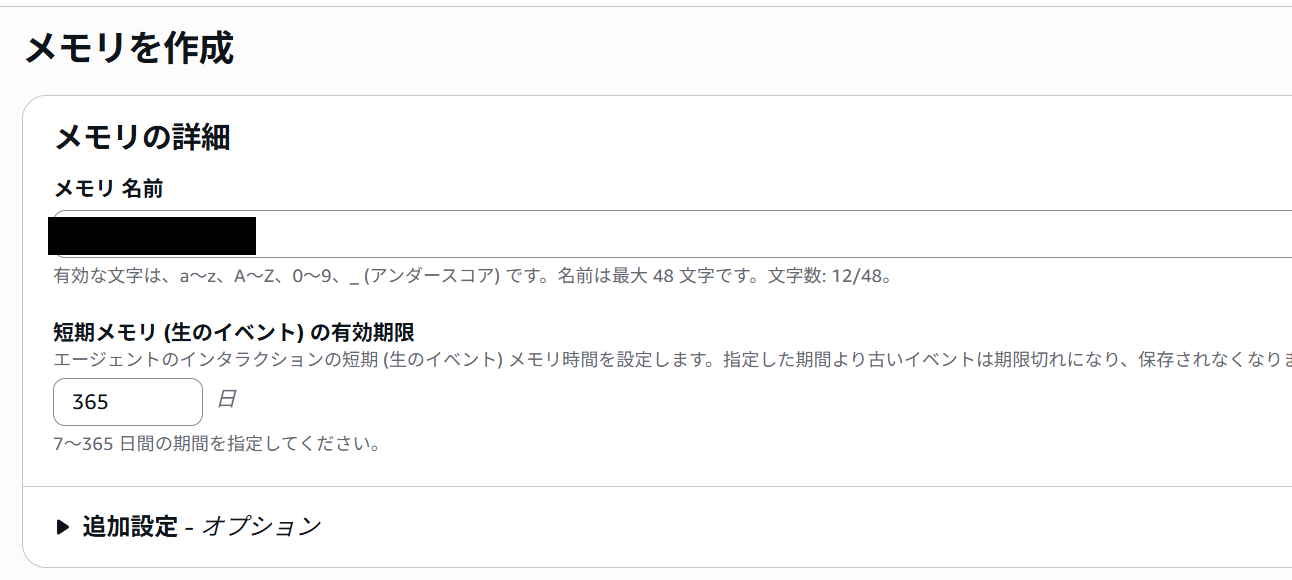
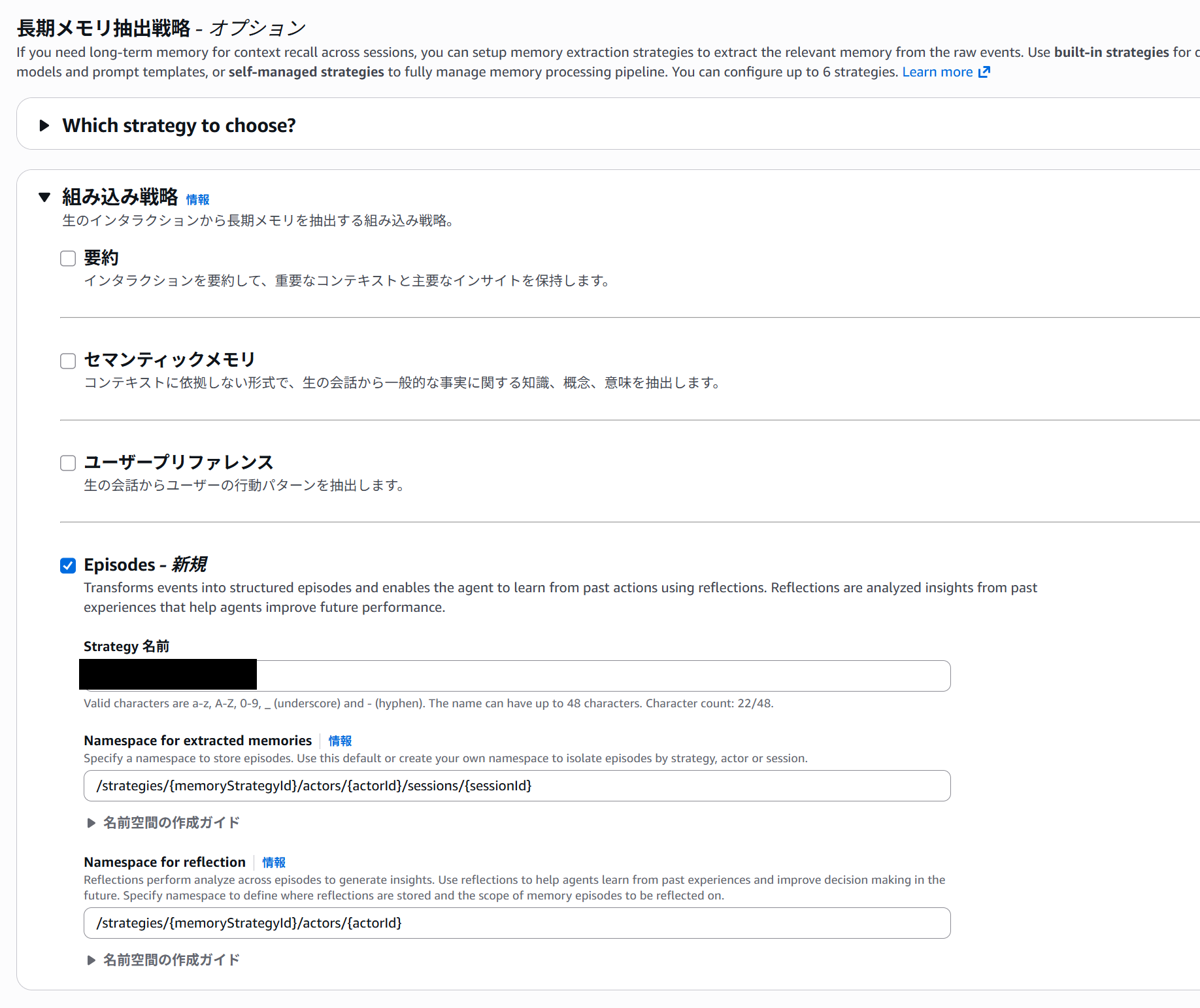
次にマネジメントコンソール上でサンプルコードが表示されるので、そのコードを基にメモリに情報を入力するLambdaを作成しました。
import json
import boto3
import uuid
from datetime import datetime
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""Lambda function to add review criteria to AgentCore Memory"""
# Memory configuration
MEMORY_ID = "memory_xxxxxx"
REGION = "ap-northeast-1"
# Initialize AgentCore Memory client
memory_client = boto3.client("bedrock-agentcore", region_name=REGION)
try:
# Extract review criteria from event
review_criteria = event.get("text", "")
if not review_criteria:
raise ValueError("text is required")
# Create session for criteria addition
session_id = f"criteria-{str(uuid.uuid4())[:8]}"
# Create payload for memory
payload = [{
"conversational": {
"content": {"text": f"新しいレビュー観点: {review_criteria}"},
"role": "USER"
}
}]
# Create event parameters
params = {
"memoryId": MEMORY_ID,
"actorId": "blog-reviewer",
"sessionId": session_id,
"eventTimestamp": datetime.utcnow(),
"payload": payload,
"clientToken": str(uuid.uuid4()),
}
# Add memory event
response = memory_client.create_event(**params)
event_data = response["event"]
logger.info("Added review criteria: %s", event_data["eventId"])
return {
"statusCode": 200,
"body": json.dumps({
"success": True,
"eventId": event_data["eventId"],
"message": "Review criteria added successfully"
})
}
except Exception as e:
logger.error("Error adding memory: %s", str(e))
return {
"statusCode": 500,
"body": json.dumps({
"success": False,
"error": str(e)
})
}
このLambdaを実行することで、メモリにレビュー観点を追加できることを確認しました。
【追加した内容】
記事内容に2024,2025年といった時間に関して、これは○○年の情報ですなど時間に関するレビュー結果を返さないでください
メモリに何が記憶されているかを確認する方法
次にメモリに何が記憶されているかを確認する方法を確認しました。
import json
import boto3
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""Lambda function to query memories using LLM prompt"""
# Configuration
MEMORY_ID = "memory_xxxxxx"
REGION = "ap-northeast-1"
MODEL_ID = "apac.anthropic.claude-sonnet-4-20250514-v1:0"
# Initialize clients
memory_client = boto3.client("bedrock-agentcore", region_name=REGION)
bedrock_client = boto3.client("bedrock-runtime", region_name=REGION)
try:
# Get user question
question = event.get("question", "どのようなレビュー観点が記憶されていますか?")
# Retrieve relevant memories
response = memory_client.retrieve_memory_records(
memoryId=MEMORY_ID,
namespace="/",
searchCriteria={
"searchQuery": question,
"topK": 10
}
)
memories = response.get("memoryRecordSummaries", [])
# Format memories for prompt
memory_context = ""
if memories:
memory_context = "記憶されているレビュー観点:\n"
for i, memory in enumerate(memories, 1):
content = memory.get("content", {}).get("text", "")
memory_context += f"{i}. {content}\n"
else:
memory_context = "現在、記憶されているレビュー観点はありません。"
# Create prompt
prompt = f"""あなたはブログレビューシステムの記憶管理アシスタントです。
{memory_context}
質問: {question}
上記の記憶内容を基に、わかりやすく回答してください。"""
# Call Bedrock
bedrock_response = bedrock_client.invoke_model(
modelId=MODEL_ID,
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
})
)
response_body = json.loads(bedrock_response['body'].read())
answer = response_body['content'][0]['text']
logger.info("Generated answer for question: %s", question)
return {
"statusCode": 200,
"body": json.dumps({
"success": True,
"question": question,
"answer": answer,
"memoryCount": len(memories)
}, ensure_ascii=False, indent=2)
}
except Exception as e:
logger.error("Error processing question: %s", str(e))
return {
"statusCode": 500,
"body": json.dumps({
"success": False,
"error": str(e)
})
}
上記のLambdaを実行することで、メモリに記憶されているレビュー観点を確認できることを確認しました。
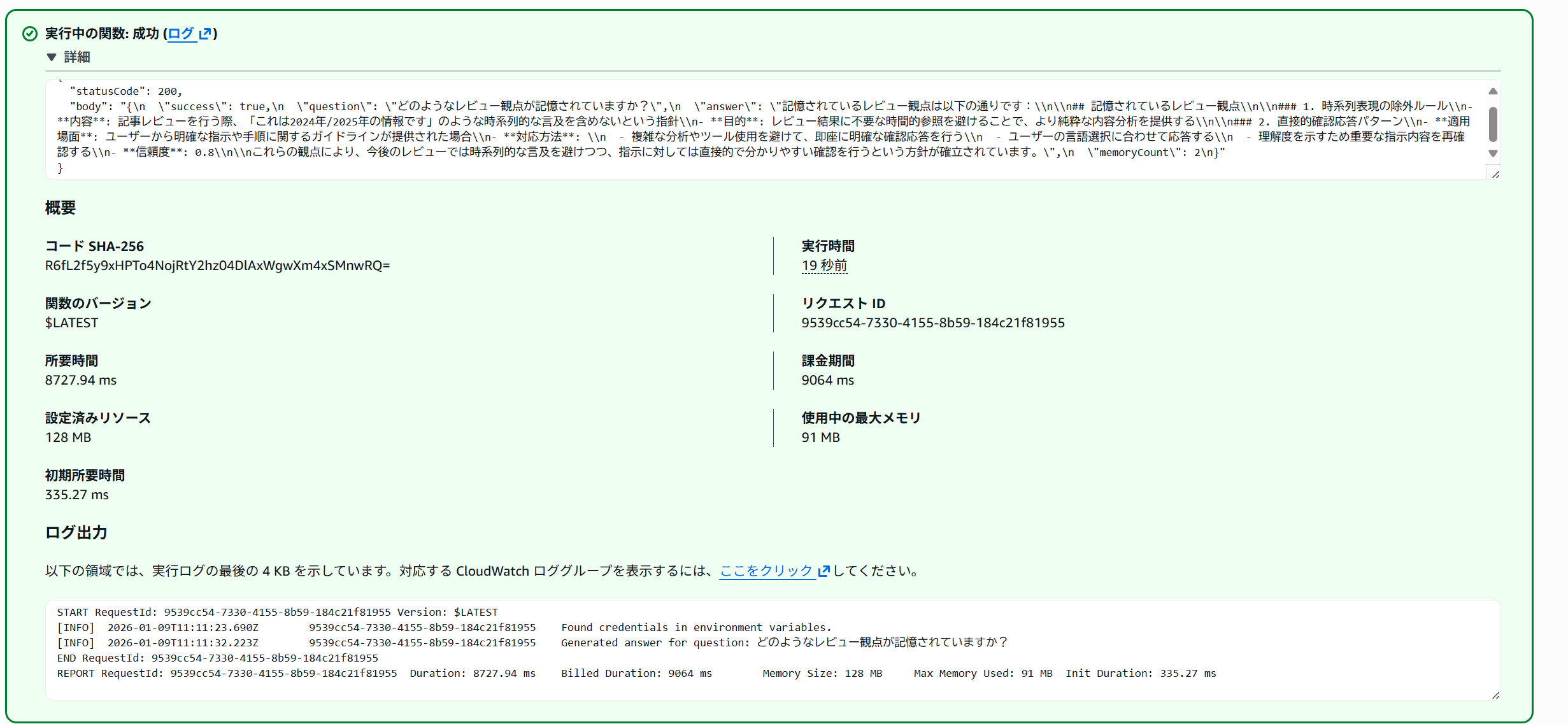
記憶されているレビュー観点は以下の通りです
記憶されているレビュー観点
1. 時系列表現の除外ルール
内容: 記事レビューを行う際、「これは2024年/2025年の情報です」のような時系列的な言及を含めないという指針
目的: レビュー結果に不要な時間的参照を避けることで、より純粋な内容分析を提供する
2. 直接的確認応答パターン
適用場面: ユーザーから明確な指示や手順に関するガイドラインが提供された場合
対応方法: 複雑な分析やツール使用を避けて、即座に明確な確認応答を行う
- ユーザーの言語選択に合わせて応答する
- 理解度を示すため重要な指示内容を再確認する
信頼度: 0.8
これらの観点により、今後のレビューでは時系列的な言及を避けつつ、指示に対しては直接的で分かりやすい確認を行うという方針が確立されています。
まとめ
Bedrock AgentCore Memoryのエピソード記憶戦略を利用することで、コードの修正やデプロイを行わずにレビュー観点を追加・確認できることがわかりました。
実際にAI Agentにメモリを組み込んだ際に期待する成果が得られるかは次の検証で実施したいと思いましたが、、、検証が終わった後に目的が「コードの修正やデプロイを行わずにレビュー観点を追加」なのでレビュー観点を外だし(S3やAWS Systems Manager Parameter Store)しておけば、Bedrock AgentCore Memoryを使用しなくてもいいと感じました。
また、レビュー観点のような「ルール・基準」を管理する場合はセマンティック記憶戦略(Semantic memory strategy)の方が適している可能性があります。
ただ手を動かしたことは無駄にはならないので、この検証がどこかで活きてくればいいなと思います。
この記事は私が書きました
小泉 和貴
記事一覧全国を旅行することを目標に、仕事を頑張っています。
